Status Aggregation for Modern IT Teams
Monitor outages, incidents, and service disruptions across all your SaaS providers from one centralized view.
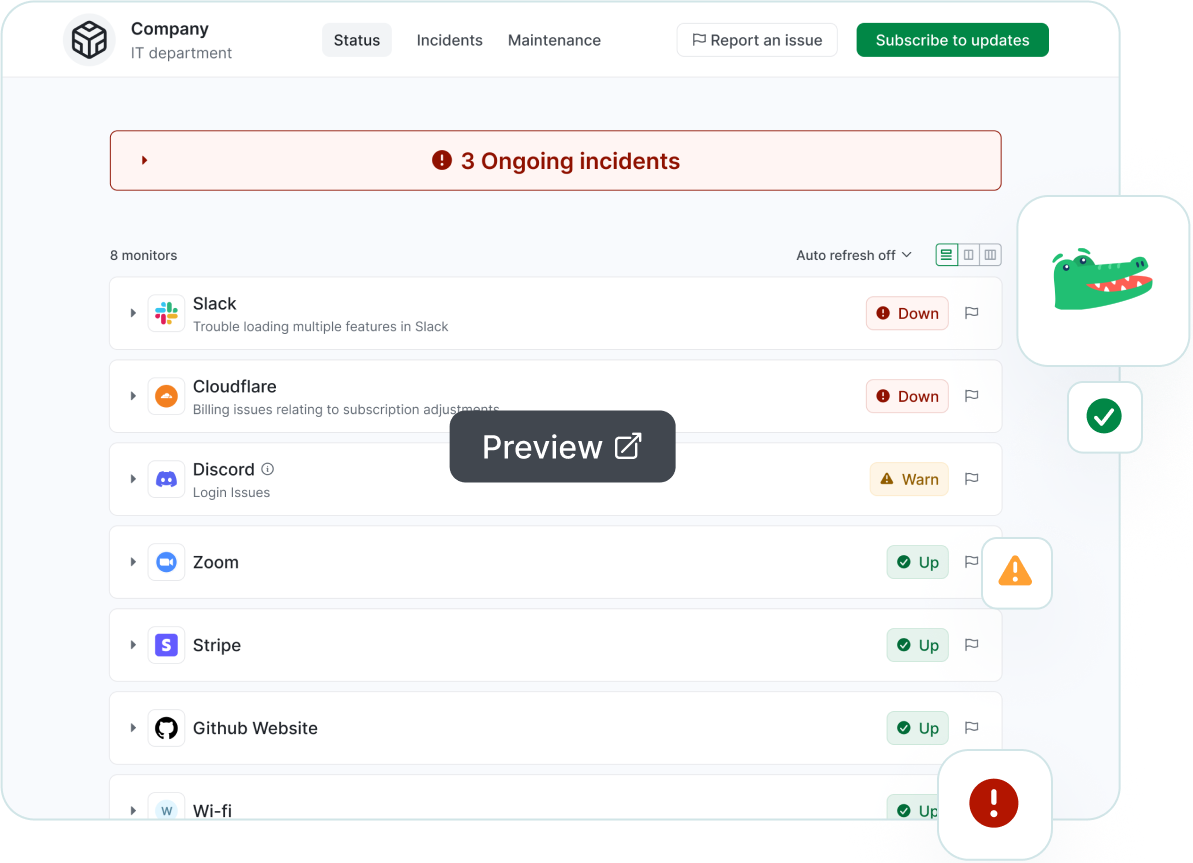
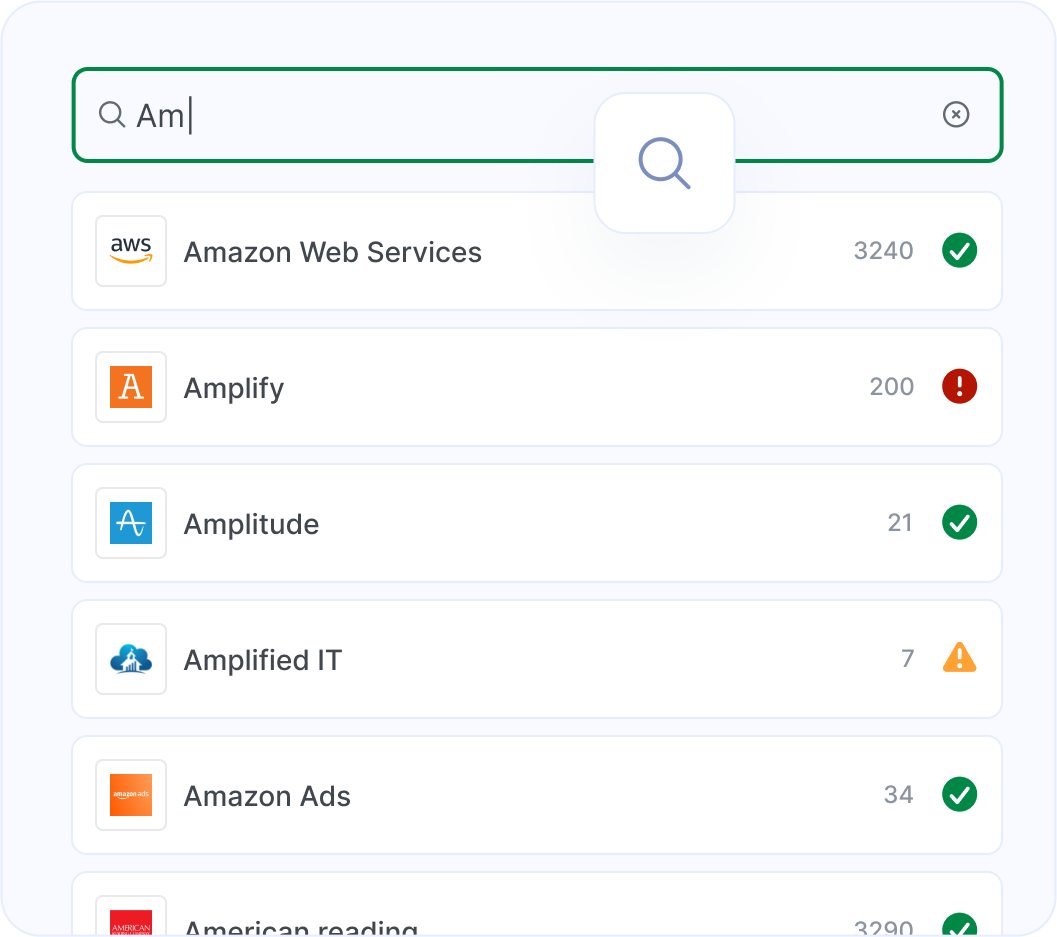
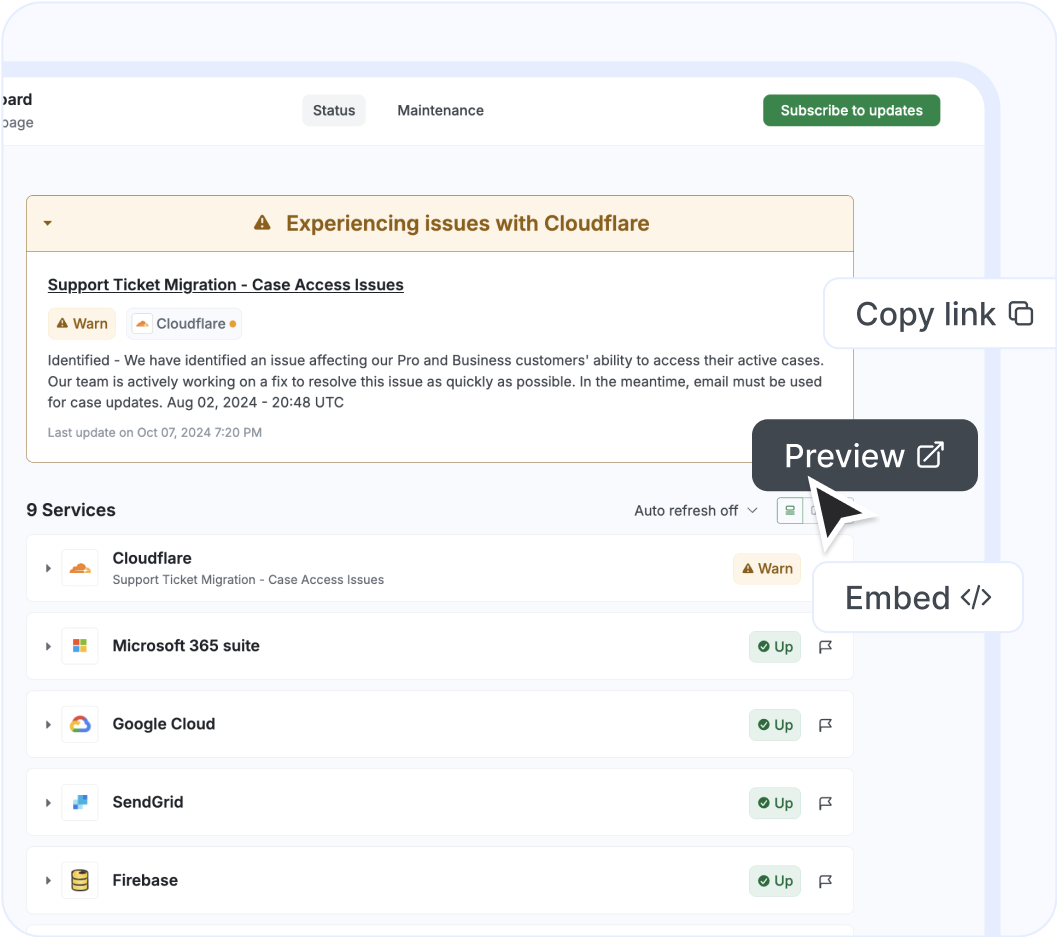
Modern businesses depend on dozens, sometimes hundreds, of cloud services. When one fails, teams waste valuable time checking scattered status pages, searching social media, and trying to determine whether the issue is internal or provider-related.
Status aggregation solves this problem by centralizing status information across your entire SaaS stack into a single operational view.